Onwards to the Core: etcd

tl;dr 🕚
The first part of the deep dive series
into the Kubernetes ListerWatcher interface jumps right into the core of
Kubernetes and its default storage backend etcd. Kubernetes uses etcd as a
distributed, strongly consistent1 and highly available key-value store. Based on
a multi-version concurrency control (MVCC) mechanism, etcd allows for time
travel queries and efficient watches (notifications) for changes in the store.
The internals of an etcd server will be explored, with a focus on its storage
engine (index and database structure) as well as how client requests and
Watches() via the various gRPC APIs are processed.
Understanding etcd will be helpful for the upcoming posts when the Kubernetes
data model and controllers comes into play. Advanced Kubernetes users might
directly want to jump into the internals, though. I recommend starting at etcd
Server.
Kubernetes in a Nutshell
Based on the learnings from internal task (container) orchestration projects at
Google2, Kubernetes is assembled of loosely coupled actors (controllers)
communicating exclusively through a REST-ful API, backed by a highly-available
and strongly consistent persistence layer (etcd):
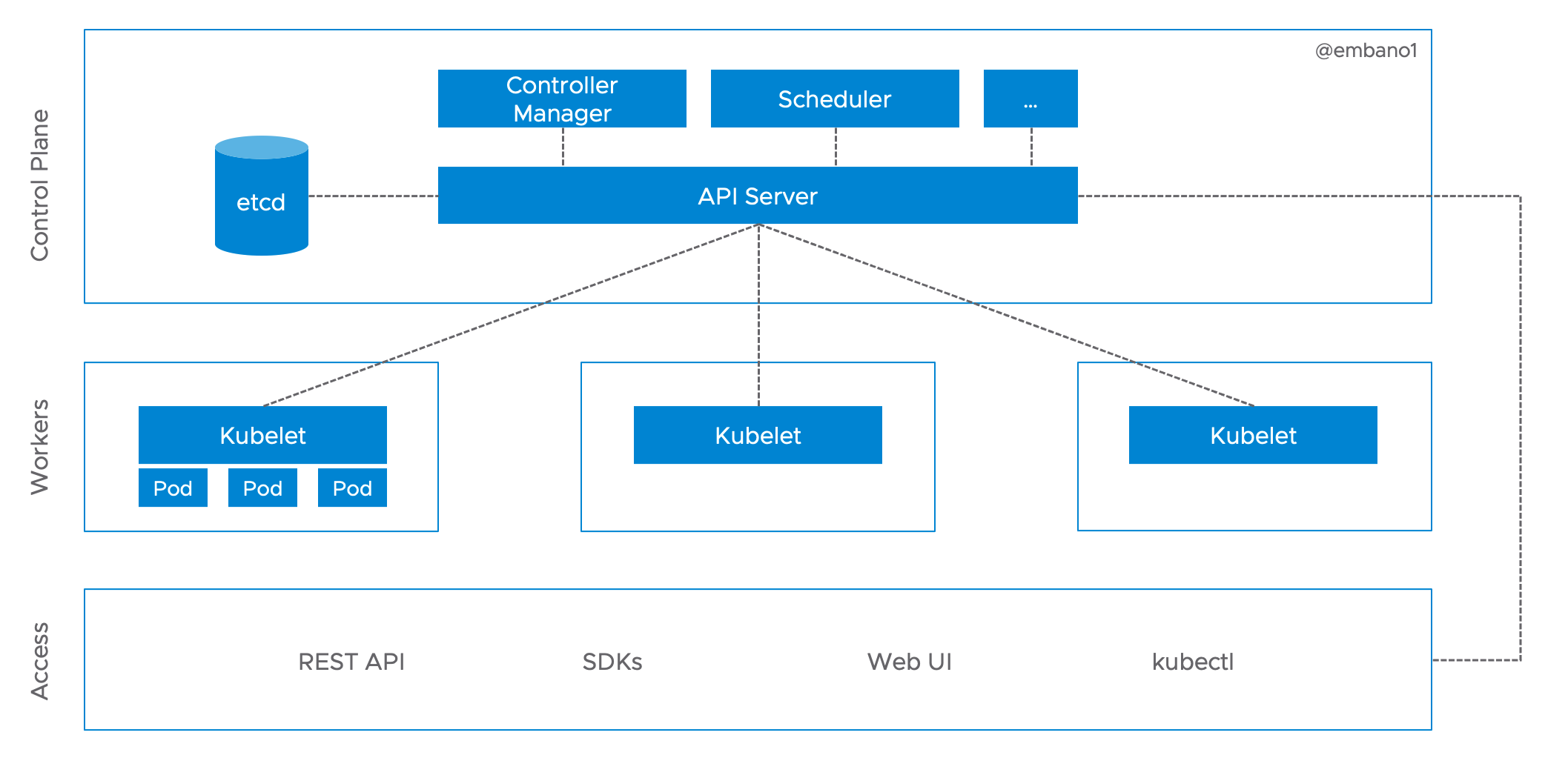
Essentially, all controllers, including the control plane components and worker agents (Kubelet), on this diagram work in the same way: they run in a continuous loop to have the current3 state of Kubernetes resources (objects) reflect the desired state. Thus, we can further simply the architecture diagram:
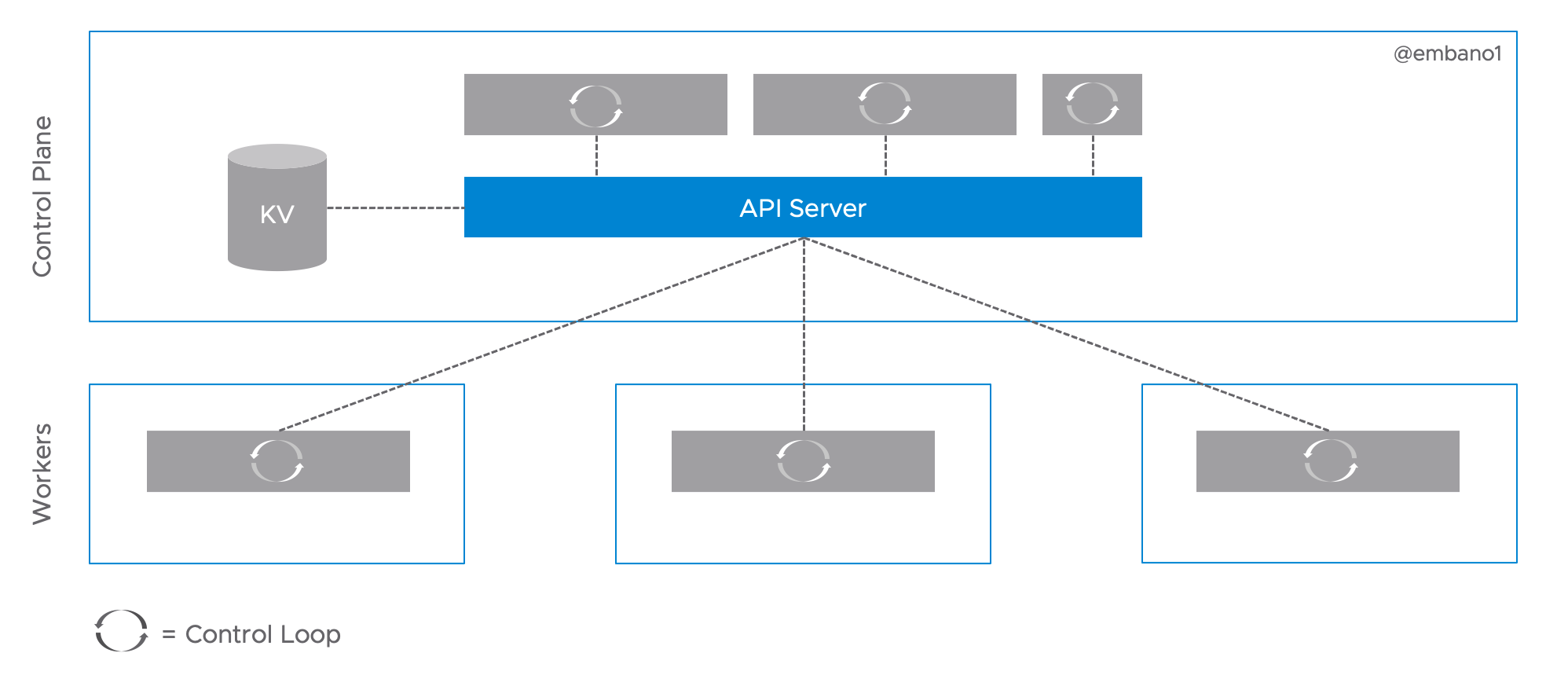
In order to reduce overall coupling (resilience) and load on the storage backend
(latency), the API server implements a push-based notification stream of state
changes (events), also known as Watch. A direct lesson from the predecessors of
Kubernetes:
Watch-like notification APIs (aka sync and tail) were common for storage systems such as Chubby, Colossus, and Bigtable. In 2013, a generalized Watch API was designed so that each system wouldn't need to reinvent the wheel. A variant "Observe" added per-entity sequencing
— Brian Grant (@bgrant0607) April 16, 2019
Why etcd?
As we will see in the next post, the API server code base is decoupled from a
concrete storage implementation. This is also true for the implementation of
Watches a Kubernetes controller can request for a particular object or list
thereof. Thus, technically, etcd can be considered an implementation detail in
Kubernetes. But as we will explore in this post, etcd is the default storage
backend for a number of reasons.
So, what is etcd anyways? To quote from the docs, etcd is a “distributed,
reliable key-value store for the most critical data of a distributed system”.
The Kubernetes creators early on decided to use etcd as the underlying
datastore, and in hindsight this decision has proven right4:
- Both projects originated at the ~same time, forming a great symbiosis over time for resilient and scalable infrastructure and application orchestration
- Like Kubernetes,
etcdis written in Go and offers a first-class SDK (clientv3) etcdexposes a key-value store API, which is a good fit for the Kubernetes object model- Support for change (event) notifications via the
Watch()API - Support for efficient RPC communication via
gRPCand protocol buffers - Support for time-travel queries via multi-version concurrency control (MVCC)
- Support for highly-available (consensus) and strict-serializable (strong consistency) reads, writes and transactions5
etcdoptionally allows for horizontal scalability6- Backed by a large open-source community and running at scale at the largest cloud providers
I’ve come to the conclusion, that if you want to fully grok the ListWatch()
implementation and optimize your Kubernetes environment, it’s good to have a
solid understanding of etcd. In addition, certain etcd details
unintentionally
leak into the
Kubernetes (API) machinery. Understanding how all the pieces fit together
definitely helps in troubleshooting. Wonder how I know 😄 ?
ListWatch() behavior, I will only cover the most important and relevant APIs
and internals of etcd. Check out Pierre’s timely
post, the official etcd
documentation or this great
talk for more details on topics we won’t
cover, e.g. consensus and transactions.Key-Value…what?
If you have never heard of a key-value store, think of it as a dictionary or
map, e.g. { "mykey": "myvalue" }. Keys must be unique and can contain
arbitrary data. In the etcd clientv3 library, the keys and values in
operations like Put() (insert/update) or Delete(), are defined as strings7.
Under the covers, these are plain []byte slices in Go (“arrays”) used in the
transport layer (gRPC) and internal data structures of etcd (see
below).
Here’s a quick example of how to interact with the key-value store of an etcd
server from the command line:
|
|
The Etcd Server
Our journey into etcd starts with the concrete EtcdServer instance where the
various parts, such as the Raft engine, datastore and APIs are
implemented. As the name suggest, ServerConfig contains settings for where to
store the various data files (DB, write-ahead log), parameters for cluster
discovery, certain limits and timeouts, etc.
|
|
The various applierV3 types also implement the public v3 API interface (gRPC),
e.g. Put(), Range(), DeleteRange() and are “applied” to the key-value
store (kv) after a successful Raft response. Note that kv also implements
the critical WatchableKV interface:
|
|
The WatchableKV interface serves two purposes. First, it is implemented by a
MVCC store, which gives us “time travel” queries as we will see later. Second,
it implements the gRPC Watch() stream API, which etcd clients like the
official clientv3 library use to
enable fast and efficient detection of changes (push instead of pull).
During the construction of our EtcdServer instance, kv is initialized by
mvcc.New() which returns a watchableStore implementing the public
interface WatchableKV:
|
|
We’re getting closer to the core. We’ll discuss the "watchable" aspect of this
object later. For now, concentrate on the embedded store.
It implements the KV interface (all caps), which has a handful of critical
methods to interact with the key-value store:
- High-level
Range()andPut()gRPC APIs to retrieve/store data - Their low-level counterparts
Read()andWrite()which are used to create consistent transactions against thestore, i.e. its key index and underlying database (bbolt) Compact()andRestore()for maintenance operations and to restore the key index upon (re)start
Here’s a high-level diagram of what we have covered thus far.
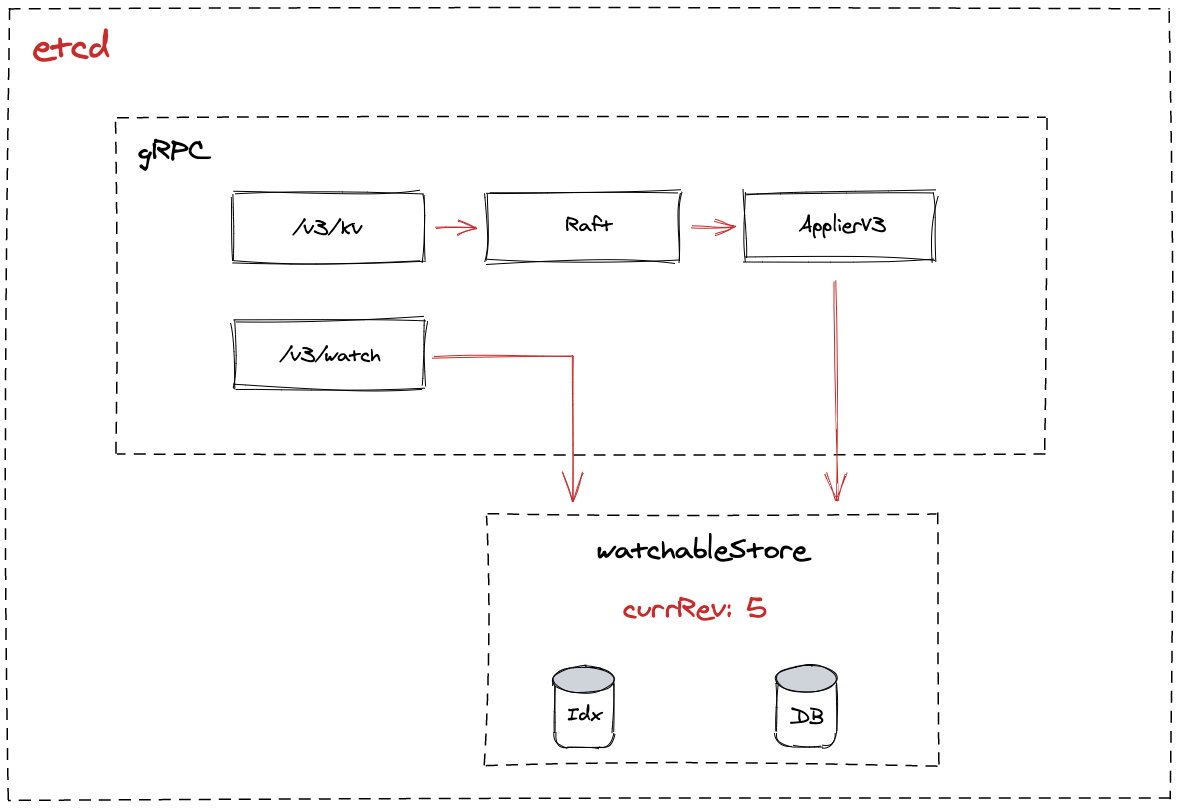
There’s a lot to unpack from here, so let’s go slowly…
All I see is Trees 🌳🌳🌳
The store is a core component in the EtcdServer and is backed by a
physical database (durability) and in-memory index structure for fast key
lookups. Upon initialization a store is set up with these fields:
|
|
Physical Backend
The database used in etcd, bbolt, is a
fork of a database created by Ben Johnson,
which is not actively maintained anymore and required some modifications to
optimize it for etcd. To quote the docs again, “Bolt is a pure Go key/value
store inspired by Howard Chu’s LMDB project. The goal of the project is to
provide a simple, fast, and reliable database for projects that don’t require a
full database server such as Postgres or MySQL.”
Besides a clean and small API, bbolt offers some nice properties as an
underlying database for etcd:
- Support for lock-free MVCC (readers never block writers, and visa versa8) implemented via a B+ tree
- ACID semantics with fully serializable transactions
Bucketsfor structuring the database and key-value space- Memory-mapped database for efficient reads
To structure the physical key-value space, one or more buckets can be created
in bbolt. Keys in a bucket must be unique and the key space is flat, i.e.
there is no hierarchy (folders, etc.) enforced. A common practice is to create a
logical hierarchy, e.g. by concatenating the keys with / as in
/servers/group-0/server-01. Filtering across these “folders”, so called range
scans, can be done with the --prefix parameter:
|
|
Note that these range scans are based on byte comparisons. I did not
explicitly create a /server key. Everything matching the string you provide
will be returned when using the --prefix parameter. Think of it like grep.
If --prefix is not specified, the behavior is exact match.
Back to our buckets. An empty etcd instance will be initialized with the
following buckets:
|
|
bbolt database.The key bucket is where etcd will persist the key-value []byte pairs sent
over the wire. One could assume that the keys in this bucket would be based on
the key name you provide during Put() operations, e.g.
/servers/group-0/server-01 from the example above.
But the etcd documentation
is pretty clear about the actual behavior: “The key of key-value pair is a
3-tuple (major, sub, type). Major is the store revision holding the key.”
Let’s ignore sub and type and focus on major, which is based on the store
revision. In the store code above we glanced over the
field currentRev. A store has a monotonically increasing counter. On each
modification of the key-value space, e.g. Put(), DeleteRange() and also
Leases()9, this counter is incremented, i.e. creating a new revision of the
store. This concept of append-only and immutable store revisions, i.e. point
in time “snapshots” or versions, forms the technical basis for MVCC, time-travel
queries and watching for changes in etcd.
An empty store starts at revision: 110. We can easily verify this with
etcdctl. Each operation, incl. those on non-existing keys, will return the
current revision:
|
|
Let’s create 4 keys and verify in the returned header that the revision now is
at 5. We request JSON-formatted output and are not interested in the values.
|
|
Note that the key output is base64 encoded above when requesting JSON
format. Each key tracks additional metadata. create_revision is the revision
this key was created. It will never change (not even during compaction),
unless you delete and recreate the key. mod_revision is the revision this key
was changed the last time and version tells us how many times this key has
been modified.
Make no mistake. Although we are still in the bbolt section, the output
returned by etcd clients, such as etcdctl, is a logical view. Next, we’re
going to use our low-level tool etcd-dump-db again to look at the physical
representation of the example above.
|
|
You might be able to guess the content from the binary representation, but we can clean this up a bit for better readability:
|
|
As described above, the key that etcd creates in the bbolt B+ tree is a
composite of [Revision.Main]_[Revision.Sub][optional:Tombstone]. The
value11 holds the opaque []byte key-value pairs clients Put() into
etcd and additional metadata which is included in the response to the
client.
Knowing the revision details (“Main” and “Sub”) of a key, we can access its
value at a specific point in time of the MVCC store. And because these revisions
are immutable, i.e. every change to the etcd key-value store (key) leads to a
new revision, the key bucket in bbolt is essentially immutable,
monotonically growing and ordered by the revision tuple.
Caveats
With a basic understanding of the (b)bolt architecture, we can briefly discuss
the caveats and limitations described in the
documentation.
#1 “Bolt is good for read intensive workloads. Sequential write performance is also fast but random writes can be slow. You can use DB.Batch() or add a write-ahead log to help mitigate this issue”.
Comment: This makes sense, given that the entire data set is likely to be served from
memory (OS page cache via mmap) during reads. etcd to the key
bucket are sequential by design, based on a monotonically growing revision key,
to avoid some of the aforementioned limitations.
#2 “Bolt uses a B+ tree internally so there can be a lot of random page access. SSDs provide a significant performance boost over spinning disks.”
Comment: The internal data structure to track memory pages pages is
lexicographically ordered by key, i.e. allows for byte comparisons and fast
range queries. However, this does not mean that the underlying data pages are
also layed out sequentially. bbolt has the concept of a freelist to recycle
unused pages.
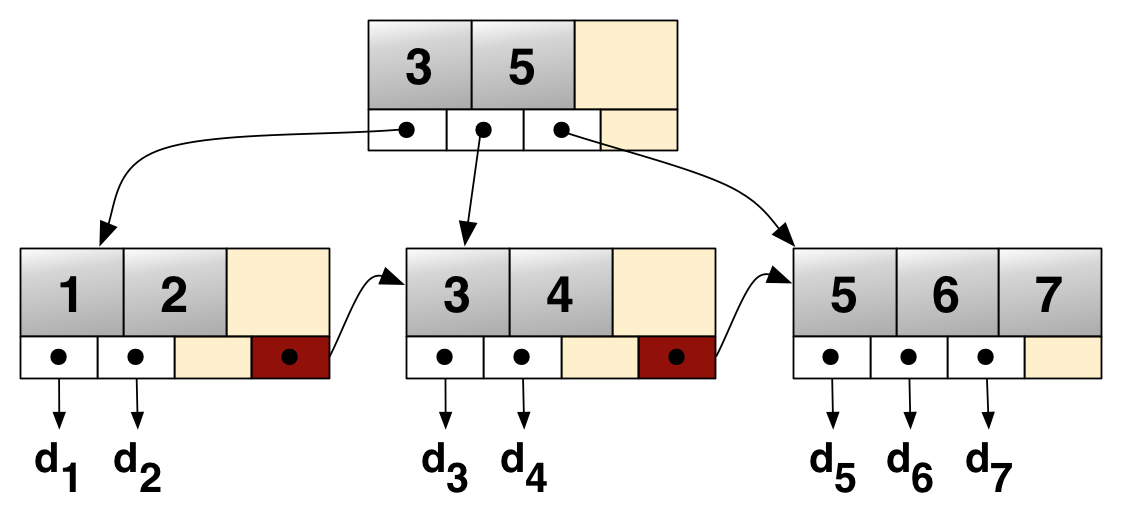
#3 “Try to avoid long running read transactions. Bolt uses copy-on-write so old pages cannot be reclaimed while an old transaction is using them.”
Comment: Best you watch Howard Chu’s talk mentioned earlier, but briefly: unused pages cannot reclaimed before the oldest transaction has finished to not risk invalid memory access. This heavily affects performance and efficiency and thus transactions should be short-lived. We’ll come back to this in a bit.
#4 “Bolt uses a memory-mapped file so the underlying operating system handles the caching of the data. Typically, the OS will cache as much of the file as it can in memory and will release memory as needed to other processes. This means that Bolt can show very high memory usage when working with large databases. However, this is expected and the OS will release memory as needed. Bolt can handle databases much larger than the available physical RAM, provided its memory-map fits in the process virtual address space.”
Comment: Nothing to add here, make sure your data set fits into RAM backed by fast disks 🤓
The Key Index
It would be very cumbersome if end users would have to query the etcd
key-value store always by revision, i.e. key in bbolt. Every application would then have to map and
track object keys to their specific revision(s) internally, e.g.:
|
|
Fortunately, etcd does this for us. The store has an internal kvindex,
created with newTreeIndex(). This index is based on the Google btree
package, an “in-memory B-tree implementation
for Go, useful as an ordered, mutable data structure”.
During an RPC call, such as Range() or Put(), the provided object key and
optionally12 a revision is internally used to construct the underlying bbolt
key (tuple) to retrieve or persist the desired value.
Because keys in the kvindex can be backed by one or more revisions, i.e.
modifications and deletions, the kvindex internally maps an object key to a
keyIndex. The keyIndex object is the data structure stored in byte-sorted
order in the in-memory B-tree index. You might recall that ranging over sorted
keys in a B(+) tree is very efficient 😉
A keyIndex item consists of a unique user-provided []byte key, a modified
revision13 and a list (slice) of generations. These are the respective
type definitions:
|
|
The generation tracks individual modifications on this specific key, e.g.
Put() and Delete().
key is deleted from etcd, it is only marked as such in the bbolt
database by appending a tombstone marker to the bbolt key. Data is never
modified in-place. The value of that tombstoned key is empty.A concrete Example
The mapping of user provided keys and associated revisions to the kvindex
and physical database can be a little bit hard to follow at first. Let’s use a
concrete example to strengthen our muscle memory 🤯
Writing Key Metadata into the Index
Assume the following sequence of store modifications, starting from an empty
store at rev=1:
|
|
This is the representation of the underlying bbolt layer:
|
|
Without compacting the kvindex, the entry for /key1 would consist of two generations
based on this flow:
- If the key does not exist, create it with a
generationholding the firstrevisionand setcreatedandver(version) accordingly - If the key is updated, append a new
revisionto the existinggenerationand incrementver - If the key is deleted, append a new
revisionto the existinggenerationand create an emptygenerationwhich is appended to thegenerationsslice of the respectivekeyIndex - If a write is performed on that key again, the last (empty) generation will
be updated with a new
revision. Theverandcreatedfields on thatgenerationare treated as if this key never existed before
bbolt datastore is updated for
consistency reasons. The in-memory index can be restored from the database.Here is a schematic representation of the current kvindex based on this
example:
|
|
Retrieving Data
In order to retrieve an object key and its value from etcd, the kvindex
performs the following steps during a Range() operation. First, it validates
the (optionally) passed revision and will return ErrFutureRev or
ErrCompacted if it is larger than the current store revision or smaller than
the one from the last compaction.
In case of a valid store revision, the next step is to retrieve the individual
revision (“position” in the database) for the given user key. Or in
simple terms, given key: /servers/group-0/server-01 what is its most recent
revision to be able to form a bbolt data query.
/servers, the
internal tree is “visited” in ascending and lexicographically sorted order,
collecting all keys matching the specified range. In a prefix scan, the
client library
constructs
an artificial end key which is used in the comparison.The next step is to iterate through the generations in the keyIndex for the
given key (or multiple thereof in case of range query). If there exist
multiple revisions for a given key, the search is performed in descending
order starting at the user-provided revision or “current” when the
caller-defined revision <= 0. Only the first matching revision will be
returned. This explains why you cannot perform a Range() query in etcd to
retrieve all revisions for a specific key. If there is no match, an empty
RangeResult will be returned (which is different from the old etcd v2 APIs
behavior).
Once we have a valid revision for that key, the actual data value will be
retrieved from bbolt. This happens in a for loop over the returned revisions
(revpairs). A revToBytes mapping is created to construct the bbolt key
and retrieve the data. The returned data value vs is unmarshaled (converted)
into the mvccpb.KeyValue type and inserted into the kvs slice which will be
eventually returned as the RangeResult.
Go code says more than a thousand words…
|
|
For completeness, here’s the type definition of kvs in the RangeResult. This
should look familiar to you by now 🤓
|
|
Sequential + Sequential = 🤯
There’s something important I want to point out to how data is retrieved in
etcd. This wasn’t immediately clear to me in the beginning and can help
troubleshooting etcd performance issues.
It is related to how keyIndices in the kvIndex map to revision tuples in
bbolt. I mentioned a couple of times that the internally used B(+) trees are
efficient especially when doing range, i.e. sequential, queries. But what if
what appears to be a range call is actually not a sequential operation at the
database layer?
Let me give you a concrete example from Kubernetes. The following bbolt view
shows all pods in the Kubernetes kube-system namespace (extracted via
etcd-dump-db). As we now know, the pods are stored (“appended”) in ascending
key order by their respective revision tuple:
|
|
Do you see the challenge from a data retrieval perspective?
The kvIndex is sorted by key in the internal B-tree, where key in this
example would be /registry/pods/kube-system/{pod-name}. Let’s sort the above
list based on kvIndex (omitting details for clarity):
|
|
Clearly, this is not a sequential range anymore and becomes more apparent in
larger clusters with infrequent writes on a small number of keys, e.g.
Kubernetes pods, whereas other keys might have more activity/churn, such as
Kubernetes endpoints. Perhaps this is why the tr.tx.UnsafeRange() call used in
the for loop above actually is not a range but “random” read: the endKey is
explicitly empty (nil), leading to a full load from the database in case of
miss in the buffer.
As we discussed in the caveats section earlier, etcd mitigates
this with buffering, aggressive caching (mmap), trying to fit the whole
dataset in memory and recommending SSDs in case of cache misses for these random
reads. Also, the physical location of the data pages in the B+ tree
implementation is random anyways. This is by design. And to be frank, before
you hit such issues, the network (Raft, TLS auth, etc.) is likely to become the
bottleneck14 in larger environments.
E = MVCC²
Before we move to the final section, I want to clarify some questions you might have around multi-version concurrency control (MVCC). I’ve mentioned this topic a couple of times throughout this post, so it must be important, right?
To recap, MVCC is a technique to create consistent point-in-time views of the database to increase concurrency while also preserving isolation between transactions. A common approach in database design15 is to create (temporary) copies16 of the internal index structures (usually a B+ tree) and use timestamps or monotonically increasing counters for causality tracking and conflict resolution (the “I” in ACID).
Keeping these copies around would be wasteful and negatively affect performance.
Thus, transactions are supposed to be short-lived17 and the index structures are regularly compacted to
free up pages. We briefly touched on this in bbolt caveats. Since
transactions, i.e. reads and writes, in bbolt are only valid for its (short)
lifetime, and key data is essentially replaced (copy-on-write), we have no way
to directly query for previous versions on a specific key in bbolt.
"AS_OF" queries in SQL.
However, it was deprecated in
v6.2 for the aforementioned performance reasons. Workarounds like
triggers and the
btree_gist
module might help, but have their own limitations. Consider using Change Data
Capture (CDC) adapters like
Debezium
in such cases.In order to support time travel queries and long-running
watches starting at an arbitrary point in time, etcd
models a multi-version store on top of bbolt. The idea is simple: If you never
overwrite a key, i.e. append-only, its history is preserved.
Thus, knowing the logical “timestamp” (here revision tuple as monotonic
clock), we can explicitly query the store state at any given point in time.
You have seen it already in action when we discussed the kvindex,
generations and revisions in depth.
To recap, here’s an example of the flow triggered by a client requesting the
value for /Key-1 at a specific time (revision). The store first retrieves
the location for that key in the database via an index lookup, followed by a
read transaction in the database at that specific revision.
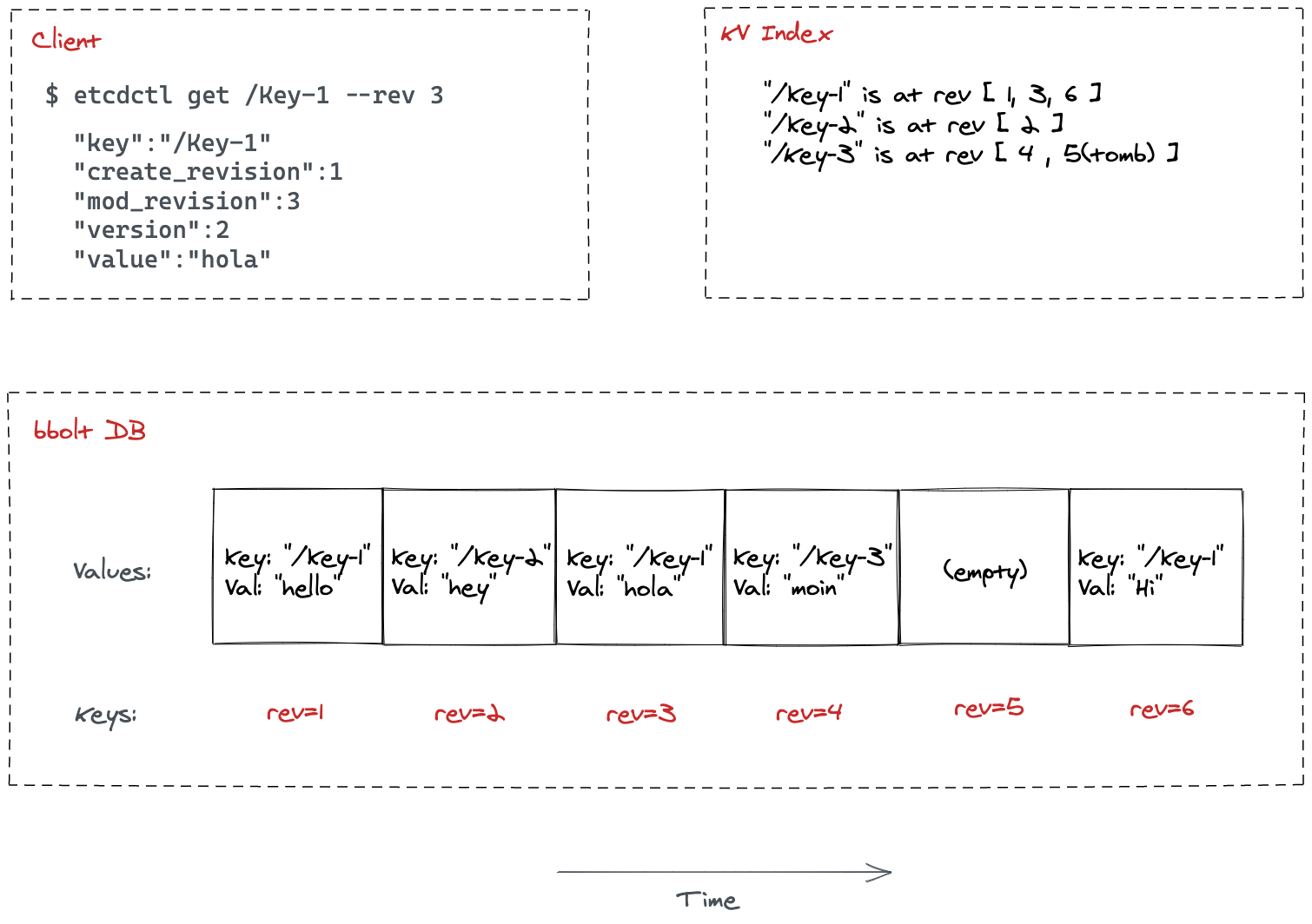
go.etcd.io/etcd/v3/server/mvcc.A Note about Compaction
Architecture is all about tradeoffs. And the design of the immutable key-value
store in etcd, based on multi-version concurrency control, is no
different here. Because data is never modified in place, the key-space will
eventually exhaust physical resources (disk space or memory) - with dramatic
consequences for the performance and stability of an etcd cluster.
etcd addresses this by periodically compacting the index and database.
Compaction itself is a rather simple process: find all revisions which are no
longer in use (or older than the specified compaction range) and delete the
associated data and kvindex entries. The freed pages will be reused for new
writes. If a key is still valid but has multiple revisions (generations),
which is smaller or equal than the specified compaction revision, only the
largest one will be kept, unless it is a tombstone.
Compaction can be triggered manually, e.g. with etcdctl, programmatically
through the clientv3 SDK, or periodically based on a schedule. The store
internally tracks the last compaction in compactMainRev. This value is updated during a
compaction for the desired compaction point (revision).
revisions smaller than the last compaction value.Wait! What happens to keys which are still valid (not deleted) but were
created at a revision smaller than the desired compaction point? Can I still
query these?
Yes, these keys are not purged, because that would render etcd pretty
useless, right 😄 ? They will be kept and returned in Range() queries. But you
cannot perform a query on them with their respective revisions because you’d
be fenced off by the compactMainRev check. The following example demonstrates
this:
|
|
Watches, finally!
Now that we have dissected all the important details of how data is persisted in
and retrieved from etcd, we can finally cover the Watch() implementation.
Watches are very important because they give developers the best of both
worlds: time-travel queries and push notifications when something happens
on key or range a particular client is watching.
Without push notifications, clients would have to continuously query (poll) the server to detect changes. Polling can be troublesome because the frequency should be minimal so clients don’t miss changes. But this has a direct impact on the latency (responsiveness) and efficiency (resource usage) on the server side - especially with a large number of clients and high churn in the key-space.
Also, no matter how low you set the polling frequency, you are not guaranteed to
see every change unless you periodically reconcile your view with queries based
on the last seen revision. But then compaction might get into your way…
Long story short, polling has a lot of drawbacks for reliably detecting changes
and should be avoided when working with etcd. Instead, go Watch()18
the (key) space 😄 !
Watches and Streams
One of the reasons why watches are so efficient is because they’re implemented
via the gRPC
streaming
APIs. Essentially, streams keep a persistent connection between two peers.
etcd uses bidirectional streams so that clients can send control messages
(WatchRequest) to register or cancel a Watch(), while the server can send
WatchResponses, e.g. events or status information, back to the clients.
clientv3 library by default multiplexes Watches() on the same client to
one underlying gRPC stream.A Watch() stream supports all the semantics we’ve discussed in the KV topic, such as:
- Starting from a specific
revisionin thestore19 Range()semantics- Filtering, e.g. based on
revisionnumber - Receiving the previous key-value pair (if available)
Who watches the Watcher?
The etcd gRPC Watch() API is exposed as a separate streaming API under
/v3/watch and implemented by a watchServer which has access to
WatchableKV. Quick refresher on this interface:
|
|
We already know about the KV store, but haven’t discussed Watchable yet. This
interface is required to create the underlying links, i.e. Go channels,
between the gRPC watchServer and the store whenever a client calls the
Watch() API.
Upon creation of the WatchableKV when the etcd server starts, it starts a
couple of Goroutines to periodically sync all registered watchers. Let’s see how
a watcher comes to life…
Registering a Watch() Stream
Every gRPC call on the Watch() API internally creates a new
serverWatchStream. This then calls the NewWatchStream() method on
WatchableKV which internally creates a watchStream that is backed by a
channel to carry WatchResponses (events). Clear as mud, right 😄 ?
Once the data structures are in place serverWatchStream kicks off two
long-running Goroutines: recvLoop() which accepts client requests and
sendLoop() that pushes responses back to the client.
The recvLoop() handles WatchRequests from the clients and internally
forwards them to register the Watch() on the store via the watchStream,
incl. details on the desired start revision, key/range, filters (specific
events only), etc.
Synchronizing Watchers
Every ~100ms all watchers are synchronized. The watcher with the lowest last
synchronized revision is picked as a point-in-time reference to avoid any
gaps in the event stream. Next, exactly one bbolt range query is performed
to retrieve the key-value items that have changed in the meantime, starting at
bbolt_key(lowest_rev) and ending at store(curRev + 1). Note that the index
does not need to be involved here at all!
Then, the retrieved bbolt key-value pairs are transformed to events. An
Event has the following structure:
|
|
In a for loop, each watcher processes the events with any filters applied
before sending it to the watcher’s internal channel. It is also ensured that a
watcher will not see duplicate events by only sending out events with
Kv.ModRevision >= watcher.minRev.
If the event channel is blocked20 (full), the watcher is considered a
victim and will be retried in a separate Goroutine with a more aggressive 10ms
ticker.
Watch() will be cancelled.The watcher channel is drained by the sendLoop() of the serverWatchStream
that was initially created on a client request. As the name suggests, this loop
reads from the event channel and creates an outgoing WatchResponse which will
eventually be sent over the gRPC stream back to the client.
If the client indicated that it wants the previous key before the actual event,
sendLoop performs an additional query (one per event), but this time through
the kvindex.Range() function to retrieve the corresponding key-value pair(s)
at the logical time event.KeyValue.ModRevision - 1. There can be cases where
the lookup fails, e.g. due to compaction or deletion, thus PrevKv is not
guaranteed to be always populated.
This is how the response to the client will look like under normal operations (added annotations for clarity):
|
|
Watch Flow
To conclude on this topic, here’s an amateurish visualization attempt to
summarize what’s going on behind the Watch() scenes.
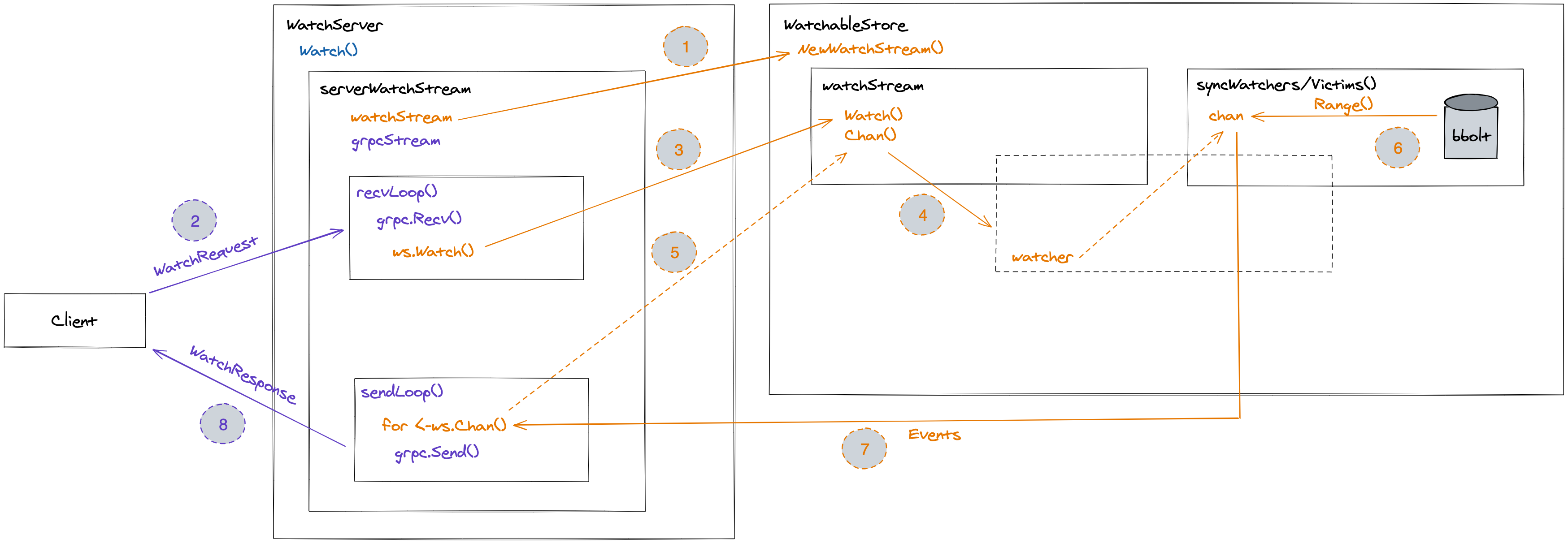
The List & Watch Pattern
A general pattern you’ll see in applications interacting with etcd, such as
Kubernetes, is the List & Watch pattern. We will discuss this in depth in the
following articles. But since it can be considered a useful pattern even outside
the scope of Kubernetes, I wanted to briefly touch on it.
Let’s say you need to process a list of users under /registry/users in etcd
and perform an action on each item. Another requirement: your application must
be stateless, because this makes our life so much easier, right?
A Watch() alone won’t be helpful here because we don’t know the exact starting
point, i.e. revision which includes all users. And by default Watch() will
start from revision(current) + 1, i.e. the next upcoming change in the
store. Yes, we could periodically checkpoint the last revision to an external
durable location (etcd anyone?), and if we crash start from that
position21.
But there’s a much simpler way…Here’s the pseudocode how to accomplish this:
|
|
There’s many ways to skin the ListWatch() cat, but you get the idea: a quorum
read, i.e. List(), will give us a consistent “current” view of all users,
including the latest revision this read was based on when ranging through the
key-space. Since every change in etcd increases the revision, we can simply
start Watch()-ing at the next revision and thus would not miss out any
(user) event!
Simple! Brilliant! Sold!
But wait! If you paid close attention, there is still an issue here! What if our
app was down while some users were deleted? The initial List() would not
include them and we’d in fact not reconcile these users 😱 !
All controllers and operators in Kubernetes actually face the same problem. Thankfully, there is another pattern, besides checkpointing, that we can leverage here. This is a topic for another post though 😉 .
What’s next?
If you’ve made it to this point, take a deep breath! You were part of an amazing journey to the core of Kubernetes!
In the next article (coming soon), we will use our understanding of etcd to
dig into the Kubernetes API machinery. How is the Kubernetes key-space
structured and objects efficiently stored? How does the API server translate
client requests, such as ListWatch(), into the etcd v3 APIs? Which
performance optimizations were made to support large Kubernetes clusters? And
what are some of the challenges arising from that?
Stay nerdy and safe!
-
I am using the term “strong” loosely here to indicate strict serializability (see Consistency section in the Jepsen report) ↩︎
-
In a distributed system, to avoid global locks, a local observer’s view must always be considered to be behind the global (“current”) state, i.e. its view is eventually consistent. ↩︎
-
To be clear, some of the mentioned etcd features were added later, mainly driven by Kubernetes’ resiliency and performance needs though ↩︎
-
E.g. sharding the key-value space with bucketing and serving reads from followers (both currently not used by Kubernetes) ↩︎
-
I never understood why the etcd maintainers decided to use strings, convenience perhaps? Also see this issue. ↩︎
-
https://etcd.io/docs/v3.3.12/dev-guide/interacting_v3/#grant-leases ↩︎
-
This is also true for an etcd cluster. All nodes initially start at RV:1. The Raft state machine guarantees that every change is applied atomically and in order across all members in the cluster, producing a globally consistent RV. ↩︎
-
The
valueis actually a protobuf encoded object, containing the objectkeyanddata,CreateRevision,ModRevision,VersionandLease↩︎ -
If the revision is not specified (or <= 0), a quorum read is performed based on the current store revision ↩︎
-
I don’t see this field being heavily used in the code base, perhaps superseded by
generationssince v3? ↩︎ -
The monitoring section provides guidance. Optionally enable tracing output as described in this issue. ↩︎
-
See MVCC in PostgreSQL or this CMU video series ↩︎
-
In general, we’re targeting sub-second timespans here ↩︎
-
Go pun intended ↩︎
-
The default is
currentRev + 1, i.e. submit changes from “now” on ↩︎ -
The current channel buffer size is 128 items, see issue#11906 for more detail ↩︎
-
This would give us at-least-once processing semantics ↩︎





